22 - Repository
Repository
It is not a good idea to access the database logic directly in the business logic. Tight coupling of the database logic in the business logic makes applications tough to test and extend further.
Problems:
- Business logic is hard to unit test.
- Business logic cannot be tested without external systems like databases
- Duplicate data access code throughout the business layer (Don’t Repeat Yourself in code – DRY principle)
Repository Pattern
Repository Pattern separates the data access logic and maps it to the entities in the business logic. It works with the domain entities and performs data access logic.
- Dal intermingled within BLL
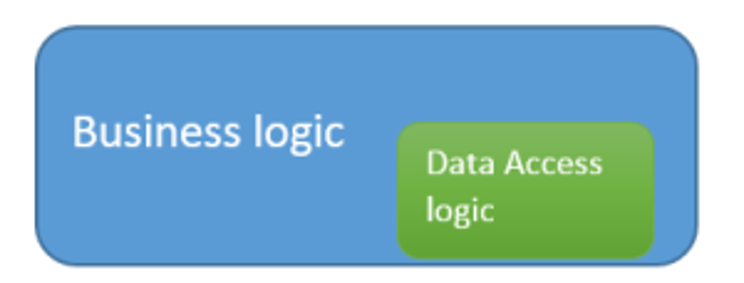
- Repository (and mappers)
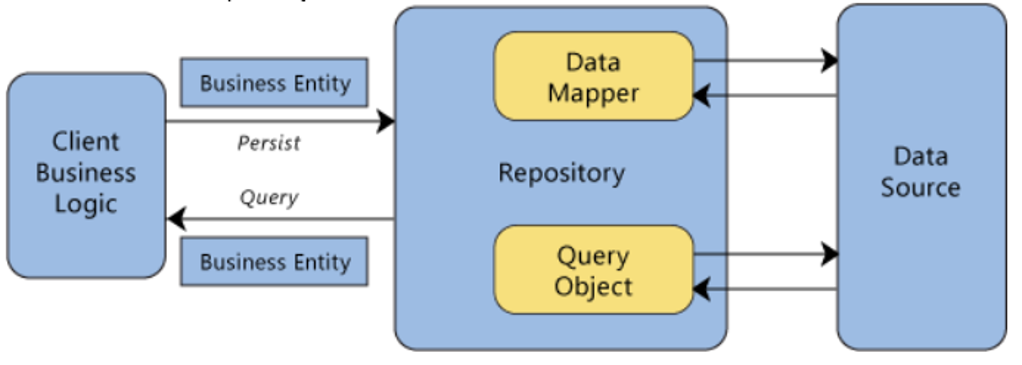
Encapsulate data processing
Encapsulate data processing
Classical way:
SqlCommand("SELECT * FROM Customer WHERE ID=" + cid).Execute
Create class instance
Copy result data into object
(NB! This is also a SQL injection vulnerability)
Repo: GetCustomerById(cid)
Repo user is not aware of where and how data is stored and retrieved (SQL, Web API, XML, CSV files, ...)
Repo types
How many and what types of repos to create?
- One per class/table
- Graph based
- Write only repo, read only repo
- One huge repo
No right answers, you must decide
Every project and team has its own customs and requirements
Repo Interface
public interface IPersonRepository : IDisposable
{
IQueryable<Person> All { get; }
IQueryable<Person> AllIncluding(
params Expression<Func<Person, object>>[] includeProperties);
Person Find(int id);
void InsertOrUpdate(Person person);
void Delete(int id);
void Save();
}
Next developer should only look at the repo interface. How repo operates - not important.
Interface is also needed for dependency injection
Repo code
public class PersonRepository : IPersonRepository
{
ContactContext context = new ContactContext();
public IQueryable<Person> All {
get { return context.People; }
}
public IQueryable<Person> AllIncluding(
params Expression<Func<Person, object>>[] includeProperties)
{
IQueryable<Person> query = context.People;
foreach (var includeProperty in includeProperties) {
query = query.Include(includeProperty);
}
return query;
}
public Person Find(int id){
return context.People.Find(id);
}
public void InsertOrUpdate(Person person) {
if (person.PersonID == default(int)) {
// New entity
context.People.Add(person);
} else {
// Existing entity
context.Entry(person).State = EntityState.Modified;
}
}
public void Delete(int id){
var person = context.People.Find(id);
context.People.Remove(person);
}
public void Save() {
context.SaveChanges();
}
public void Dispose() {
context.Dispose();
}
}
Repo in console
using ContactsLibrary;
namespace RepoConsoleApp
{
class Program
{
static void Main(string[] args)
{
using (var repo = new PersonRepository()) {
repo.InsertOrUpdate(new Person { FirstName = "Juku", LastName = "Mänd" });
repo.InsertOrUpdate(new Person { FirstName = "Malle", LastName = "Tamm" });
repo.Save();
foreach (var person in repo.All.ToList())
{
Console.WriteLine("{0} {1}", person.FirstName, person.LastName);
}
}
Console.ReadLine();
}
}
}
Repo universal interface
public interface IEntityRepository<T> : IDisposable
{
IQueryable<T> All { get; }
IQueryable<T> AllIncluding(params Expression<Func<T, object>>[] includeProperties);
T Find(int id);
void InsertOrUpdate(T entity);
void Delete(int id);
void Save();
}
public interface IPersonRepository : IEntityRepository<Person>
{
}
Repo problems
- Object graphs — when entities have navigation properties (e.g.
Person.Addresses), loading and saving entire graphs through a repository becomes complex. Which related entities should be included? Who is responsible for saving child entities? - Disposed context — if the repository disposes its DbContext, any lazy-loaded navigation properties will throw
ObjectDisposedExceptionwhen accessed later. This is a common source of bugs. - If possible, avoid deep graphs. Operate with single objects or shallow includes. (Common in Web API / MVC)
Repo recap
- Repo – container, data storage engine encapsulation
- Typically, CRUD methods - to operate on some concrete class
- Real data storage engine, with its implementation details is hidden from repo user
- Possibility to easily replace storage mechanism within application
From concrete to generic
The examples above show a self-contained repository with its own Save() and Dispose(). But if our application has 20 entities, do we write 20 nearly identical repository classes? Generics (lecture 20) let us extract the common CRUD logic into a single base implementation.
In modern architectures, we also separate saving into the Unit of Work pattern (see below).
IQueryable vs IEnumerable
Notice that the earlier examples returned IQueryable<T>, while the generic interface below returns IEnumerable<T>. This is a deliberate architectural choice:
IQueryable<T>— deferred execution. The query is not yet sent to the database; callers can add.Where(),.OrderBy()etc. and the final SQL will include those filters. But this leaks the data layer abstraction — callers can build arbitrary queries, making it harder to test and control.IEnumerable<T>— materialized results. The query runs in the repository, and callers get an in-memory collection. This provides a clean abstraction boundary but means all filtering must happen inside the repository.
There is no single right answer — it depends on project requirements. In this course we prefer IEnumerable<T> for cleaner separation.
BaseEntity
The generic constraint where TEntity : BaseEntity requires a common base class for all domain entities:
public abstract class BaseEntity
{
public Guid Id { get; set; }
}
All domain entities inherit from BaseEntity, giving them a common primary key type that the generic repository can rely on.
Repo generic interface
public interface IRepository<TEntity> where TEntity : BaseEntity
{
IEnumerable<TEntity> All();
Task<IEnumerable<TEntity>> AllAsync();
TEntity Find(params object[] id);
Task<TEntity> FindAsync(params object[] id);
void Add(TEntity entity);
Task AddAsync(TEntity entity);
TEntity Update(TEntity entity);
void Remove(TEntity entity);
void Remove(params object[] id);
}
Repo code 1
public class EFRepository<TEntity> : IRepository<TEntity> where TEntity : BaseEntity
{
protected DbContext RepositoryDbContext;
protected DbSet<TEntity> RepositoryDbSet;
public EFRepository(IDataContext dataContext){
RepositoryDbContext = dataContext as DbContext ?? throw new ArgumentNullException(nameof(dataContext));
RepositoryDbSet = RepositoryDbContext.Set<TEntity>();
}
public virtual IEnumerable<TEntity> All() => RepositoryDbSet.ToList();
public virtual async Task<IEnumerable<TEntity>> AllAsync() => await RepositoryDbSet.ToListAsync();
public virtual TEntity Find(params object[] id) => RepositoryDbSet.Find(id);
public virtual async Task<TEntity> FindAsync(params object[] id) => await RepositoryDbSet.FindAsync(id);
public void Add(TEntity entity) => RepositoryDbSet.Add(entity);
public virtual async Task AddAsync(TEntity entity) => await RepositoryDbSet.AddAsync(entity);
public TEntity Update(TEntity entity) => RepositoryDbSet.Update(entity).Entity;
public void Remove(TEntity entity) => RepositoryDbSet.Remove(entity);
public void Remove(params object[] id){
var entity = RepositoryDbSet.Find(id);
Remove(entity);
}
}
Repo code 2
public interface IPersonRepository : IRepository<Person>
{
// add custom methods
}
public class PersonEFRepository : EFRepository<Person>, IPersonRepository
{
public PersonEFRepository(IDataContext dataContext) : base(dataContext)
{
}
// implement custom methods
}
Tracking
In Entity Framework, every time EF reads records from the database, they are tracked by the ChangeTracker by default. This enables EF to detect changes for SaveChanges(), but it adds performance overhead.
If you only need to read data (not update it), you can disable tracking:
AsNoTracking()— no tracking at all. Fastest option. But if your query returns the same entity twice (e.g. through different navigation paths), you get two separate object instances.AsNoTrackingWithIdentityResolution()— no tracking, but EF still ensures that the same primary key maps to the same object instance. Slightly slower thanAsNoTracking(), but avoids duplicate objects. Common scenario when using mappers.
Or disable tracking globally for a given context:
builder.Services
.AddDbContext<AppDbContext>(options => options
.UseNpgsql(
connectionString,
o => { o.UseQuerySplittingBehavior(QuerySplittingBehavior.SplitQuery); }
)
.ConfigureWarnings(w =>
w.Throw(RelationalEventId.MultipleCollectionIncludeWarning)
)
.EnableDetailedErrors()
.EnableSensitiveDataLogging()
// disable tracking, allow id based shared entity creation
.UseQueryTrackingBehavior(QueryTrackingBehavior.NoTrackingWithIdentityResolution)
);
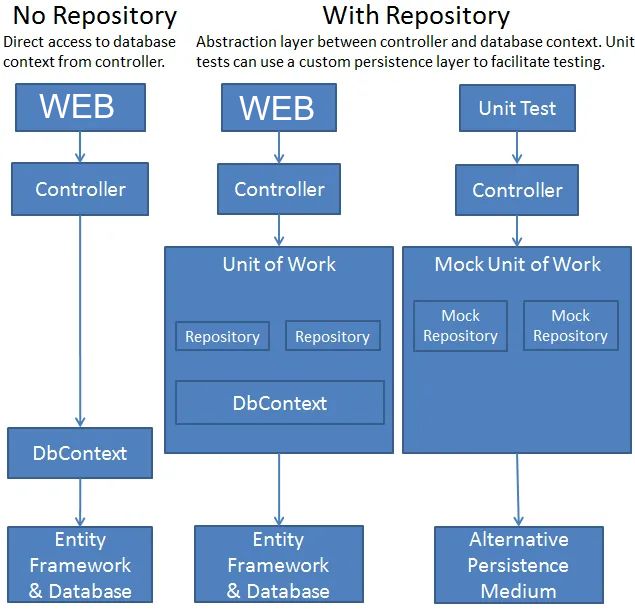
UOW
The Unit of Work pattern is used to manage transactions and ensure that multiple operations are treated as a single logical unit. It provides a way to group database operations together, ensuring that they either succeed or fail as a whole. The key principle behind the Unit of Work pattern is to maintain data consistency and integrity by committing or rolling back changes in a coordinated manner.
/// <summary>
/// Unit Of Work pattern methods - atomic save of work done so far
/// </summary>
public interface IBaseUOW
{
Task<int> SaveChangesAsync();
int SaveChanges();
}
public class EFBaseUOW<TDbContext> : IBaseUOW
where TDbContext : DbContext
{
protected readonly TDbContext UowDbContext;
public EFBaseUOW(TDbContext dataContext)
{
UowDbContext = dataContext;
}
public virtual int SaveChanges()
{
return UowDbContext.SaveChanges();
}
public virtual async Task<int> SaveChangesAsync()
{
return await UowDbContext.SaveChangesAsync();
}
}
public interface IAppUOW : IBaseUOW
{
// list your repositories here
ISomeRepo SomeRepo { get; }
}
public class AppUOW : EFBaseUOW<ApplicationDbContext>, IAppUOW
{
public AppUOW(ApplicationDbContext dataContext) : base(dataContext)
{
}
private ISomeRepo? _someRepo;
public ISomeRepo SomeRepo =>
_someRepo ??= new SomeRepo(UowDbContext);
}
UoW usage example
How does a controller use the UoW with repositories?
public class SomeController : Controller
{
private readonly IAppUOW _uow;
public SomeController(IAppUOW uow)
{
_uow = uow;
}
public async Task<IActionResult> Create(SomeCreateViewModel vm)
{
var entity = _mapper.Map<SomeEntity>(vm);
_uow.SomeRepo.Add(entity);
await _uow.SaveChangesAsync();
return RedirectToAction("Index");
}
public async Task<IActionResult> Delete(Guid id)
{
_uow.SomeRepo.Remove(id);
await _uow.SaveChangesAsync();
return RedirectToAction("Index");
}
}
All repository operations within a single request share the same DbContext through the UoW. When SaveChangesAsync() is called, all changes across all repositories are committed in a single transaction.
But how does IAppUOW get into the controller constructor? That is Dependency Injection — next lecture.
Repository Pattern debate
EF Core's DbContext is itself already a Unit of Work (SaveChanges) and Repository (DbSet<T>). So why add another layer on top?
Arguments against the extra repository layer:
- It can become a thin wrapper that adds complexity without real benefit
- EF Core is already testable (in-memory provider, SQLite)
Arguments for the repository layer (and why we use it in this course):
- Clean separation — business logic does not depend on EF Core directly
- Easier to swap data access technology (e.g. replace EF with Dapper or a Web API call)
- Enforces consistent data access patterns across the team
- Simpler unit testing with mock/fake repositories
In real projects, evaluate this trade-off based on project size and team needs. For this course, we use repositories to practice layered architecture and clean separation of concerns.
Self preparation QA
Be prepared to explain topics like these:
- Why use the Repository pattern when EF Core's DbContext already implements Repository and Unit of Work? — The repository layer creates a clean separation where business logic does not depend on EF Core directly. It makes data access technology swappable and simplifies unit testing.
- What is the Unit of Work pattern and why separate it from repositories? — Unit of Work groups multiple repository operations into a single transaction. All repos share the same DbContext, and
SaveChangesAsync()commits everything atomically. - Why return
IEnumerable<T>instead ofIQueryable<T>from repositories? —IQueryable<T>defers execution and lets callers build arbitrary database queries, leaking the data layer abstraction.IEnumerable<T>materializes results inside the repository, creating a clean boundary. - Why use a
BaseEntitywith a commonIdproperty? — The generic constraint requires all entities to share a primary key type, letting the generic repository implementFindById,Remove(id), and new-vs-existing checks. - What is the disposed context problem with repositories? — If a repository disposes its DbContext, lazy-loaded navigation properties accessed later throw
ObjectDisposedException. In ASP.NET Core, the DI container manages DbContext lifetime. - What are the trade-offs between
AsNoTracking()andAsNoTrackingWithIdentityResolution()? —AsNoTracking()is fastest but creates duplicate object instances for the same entity.AsNoTrackingWithIdentityResolution()maintains identity mapping at slightly more cost.