90 - Machine Learning, LLMs and AI in SWE
Intro to ML
Machine learning (ML) powers some of the most important technologies we use, from translation apps to autonomous vehicles.
ML offers a new way to solve problems, answer complex questions, and create new content. ML can predict the weather, estimate travel times, recommend songs, auto-complete sentences, summarize articles, and generate never-seen-before images.
ML Systems
ML systems fall into one or more of the following categories based on how they learn to make predictions or generate content:
- Supervised learning
- Unsupervised learning
- Reinforcement learning
- Generative AI
Supervised learning
Models can make predictions after seeing lots of data with the correct answers and then discovering the connections between the elements in the data that produce the correct answers. This is like a student learning new material by studying old exams that contain both questions and answers.
Regression A regression model predicts a numeric value. For example, a weather model that predicts the amount of rain, in inches or millimeters, is a regression model.
Future house price
Square metres, region, number of bedrooms and bathrooms, lot size, mortgage interest rate, property tax rate, construction costs, and number of homes for sale in the area.
Classification
A classification models predict the likelihood that something belongs to a category. Unlike regression models, whose output is a number, classification models output a value that states whether or not something belongs to a particular category.
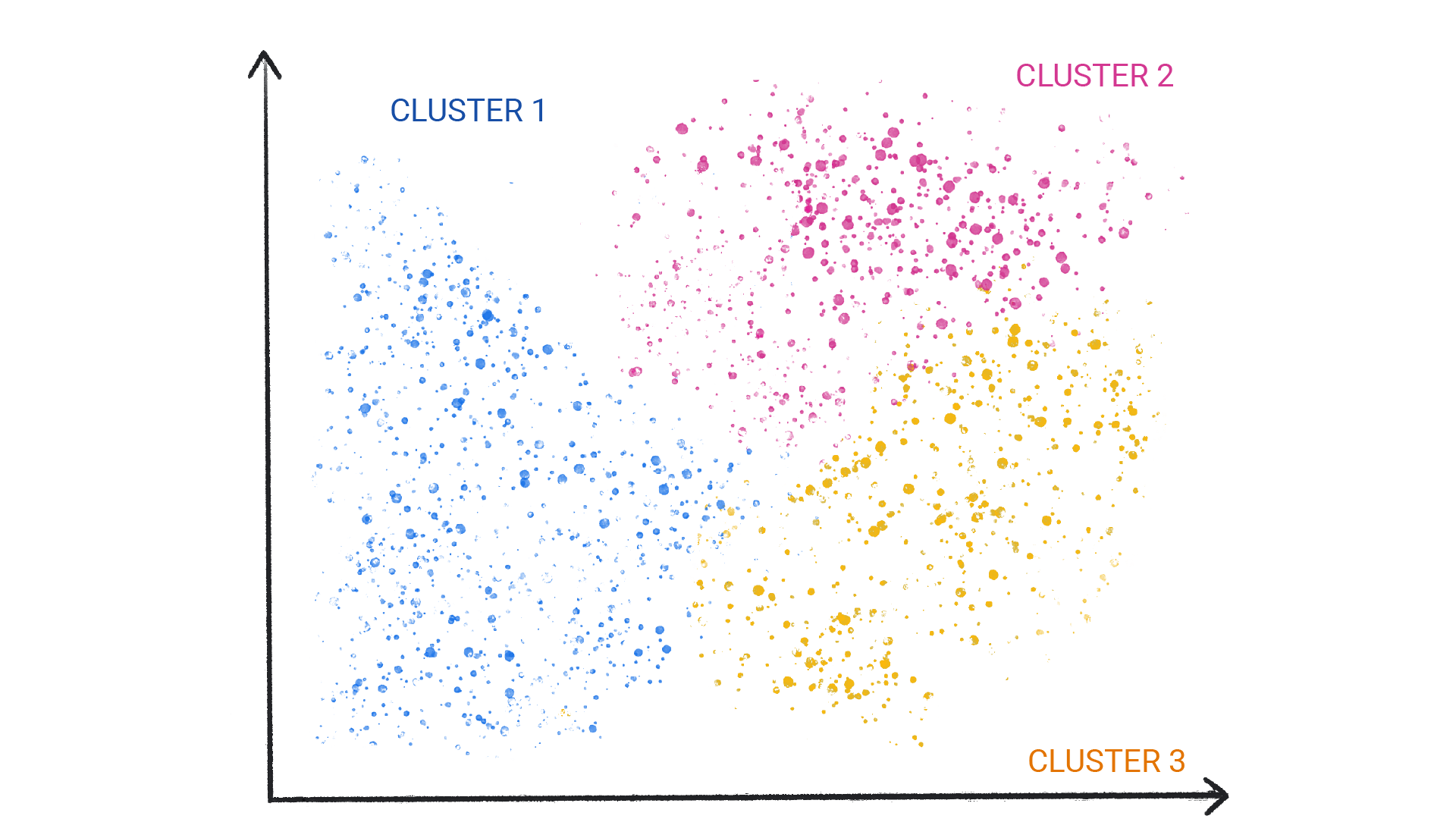
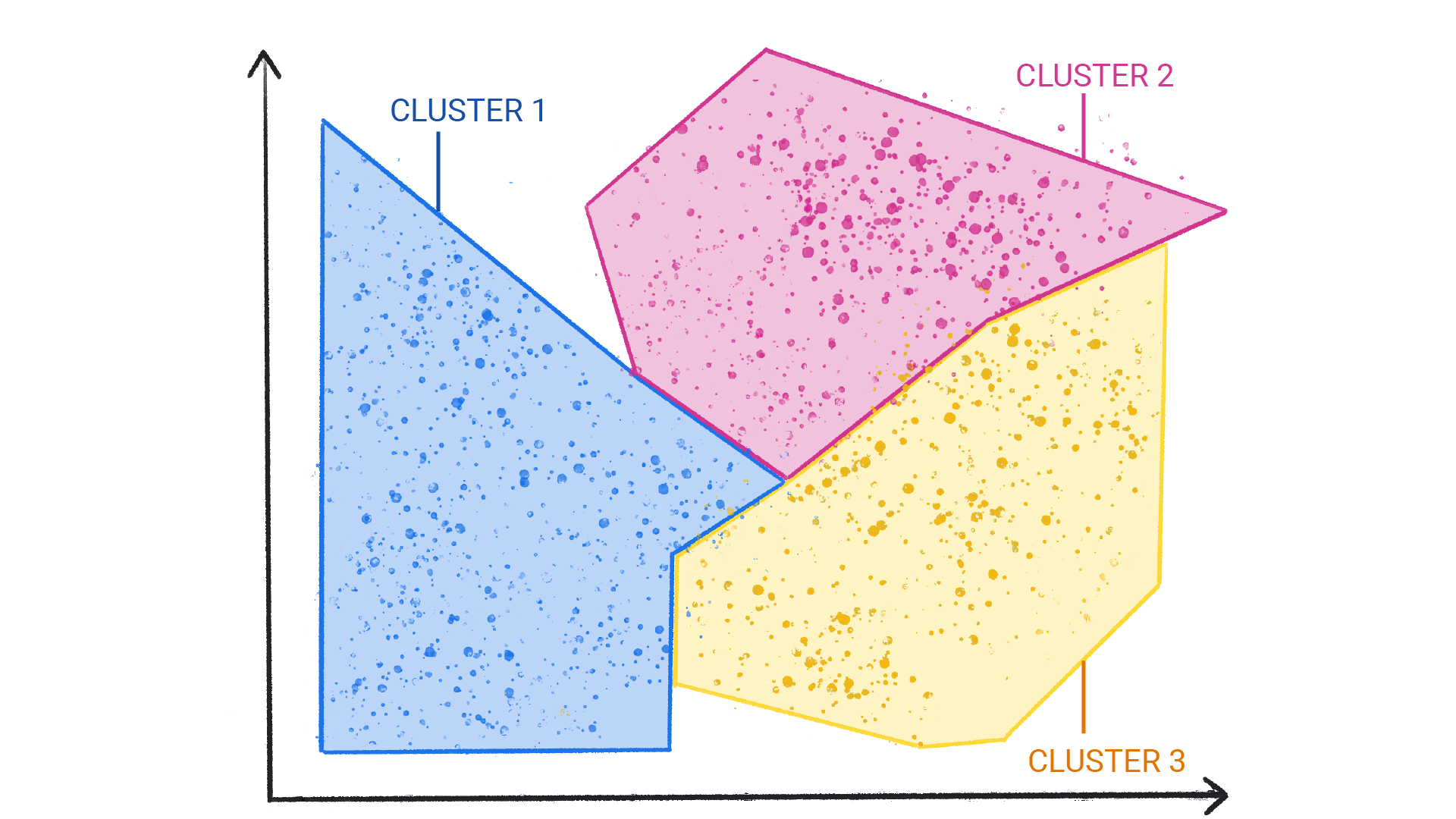
Unsupervised learning
Unsupervised learning models make predictions by being given data that does not contain any correct answers. An unsupervised learning model's goal is to identify meaningful patterns among the data.
Reinforcement learning
Reinforcement learning models make predictions by getting rewards or penalties based on actions performed within an environment. A reinforcement learning system generates a policy that defines the best strategy for getting the most rewards.
Robot walking, AlphaGo
Generative AI Generative AI is a class of models that creates content from user input.
- Text-to-text
- Text-to-image
- Text-to-video
- Text-to-code
- Text-to-speech
- Image and text-to-image
At a high-level, generative models learn patterns in data with the goal to produce new but similar data. To produce unique and creative outputs, generative models are initially trained using an unsupervised approach, where the model learns to mimic the data it's trained on. The model is sometimes trained further using supervised or reinforcement learning on specific data related to tasks the model might be asked to perform, for example, summarize an article or edit a photo.
ML & AI
Initially there was just lots of statistics. Most classical maybe of them is linear regression.
For example, fuel economy might depend on
- weight
- engine size
- fuel type
- power
- cylinder count
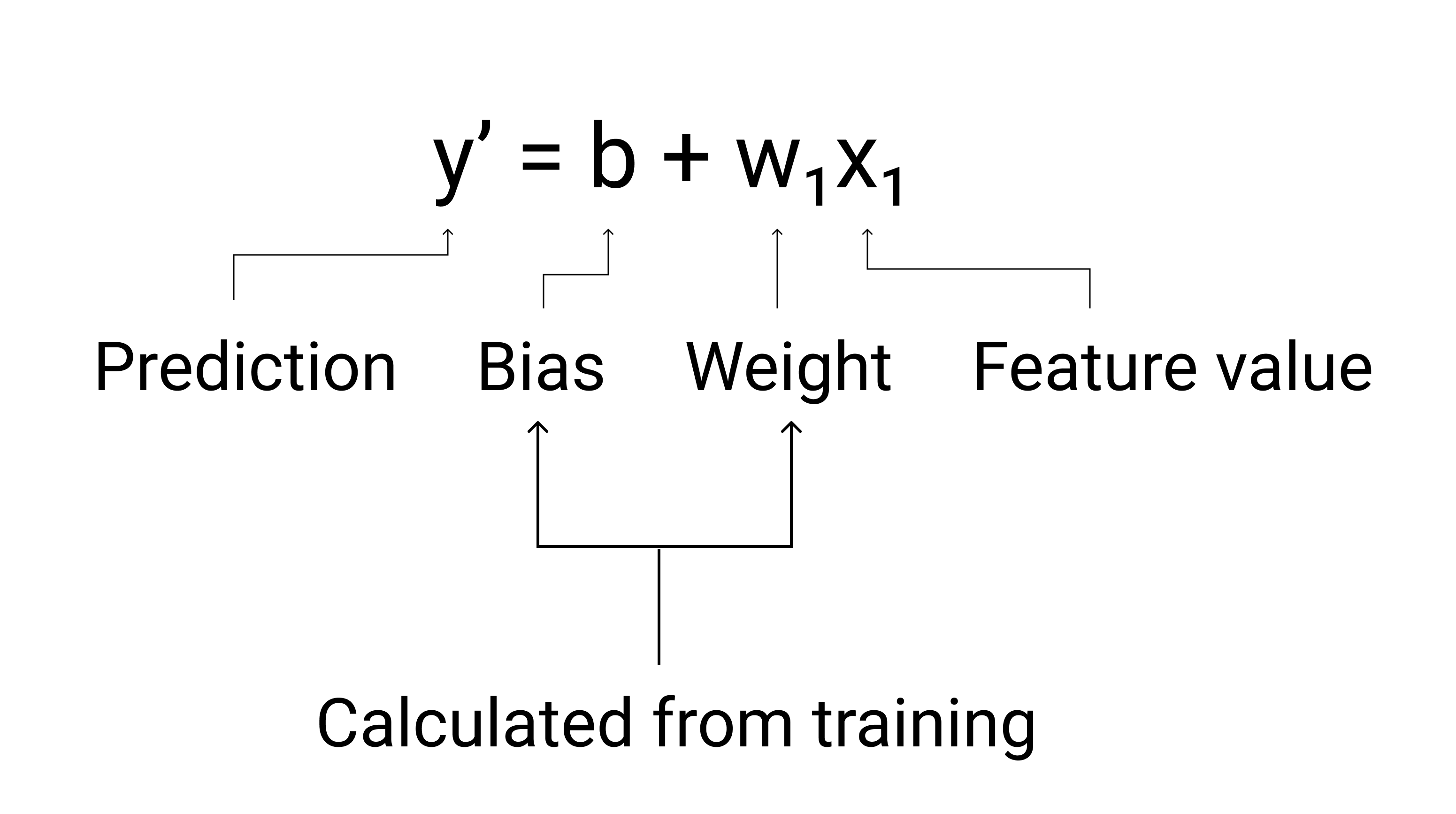
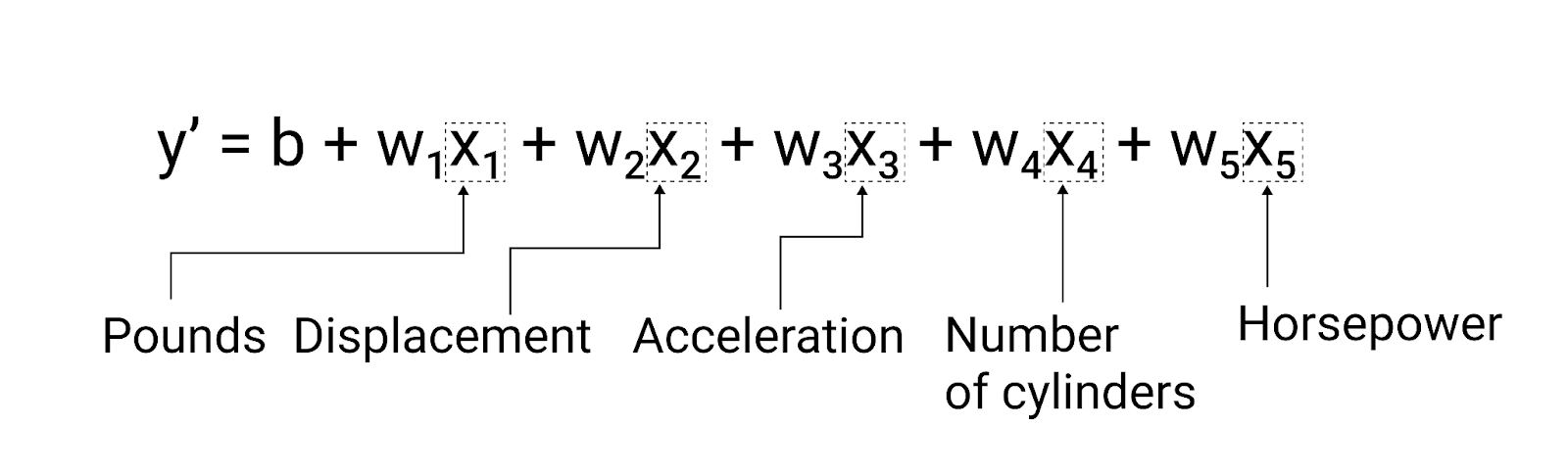
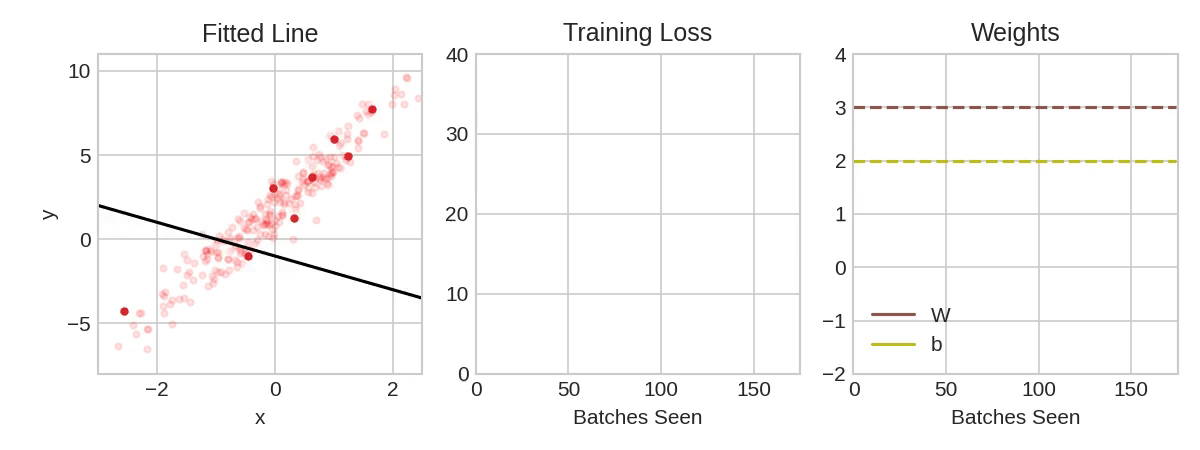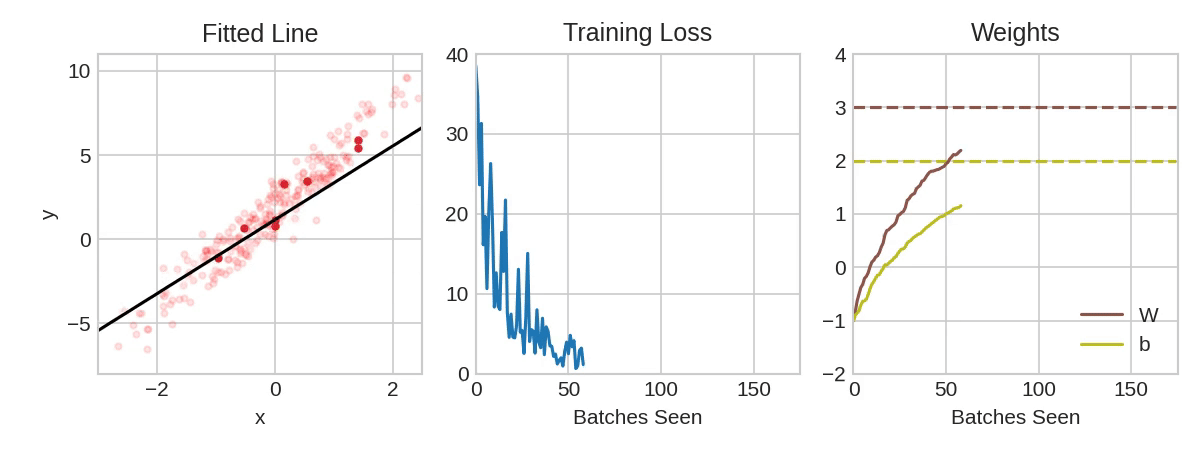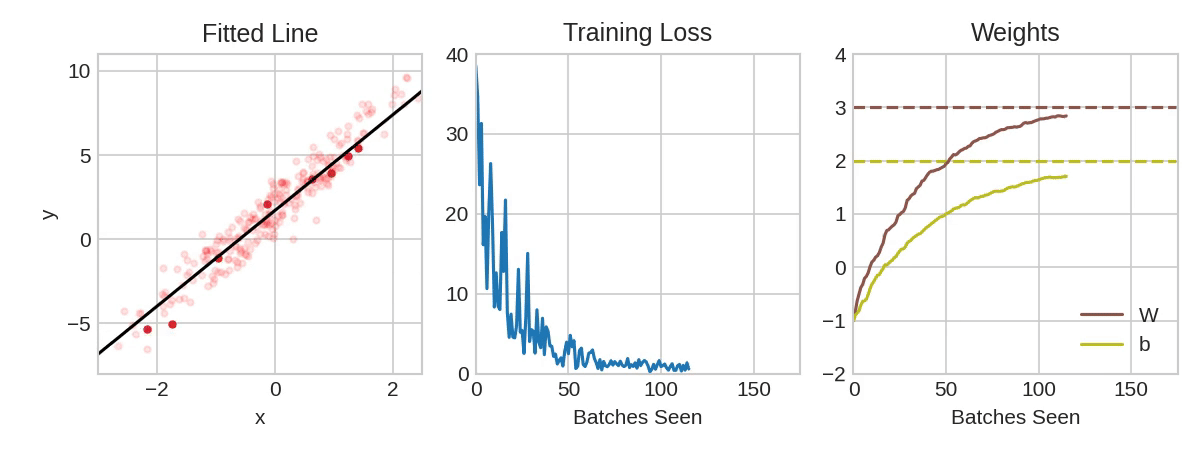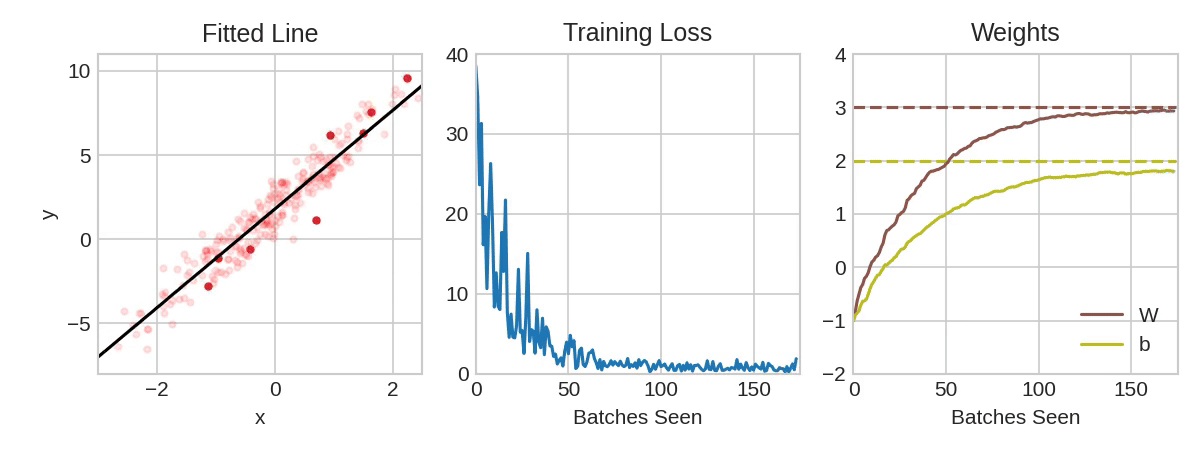
Based on examples we try to calculate the bias and weights. Or just try different values randomly.
To measure the quality of found formula - loss is calculated (loss function).
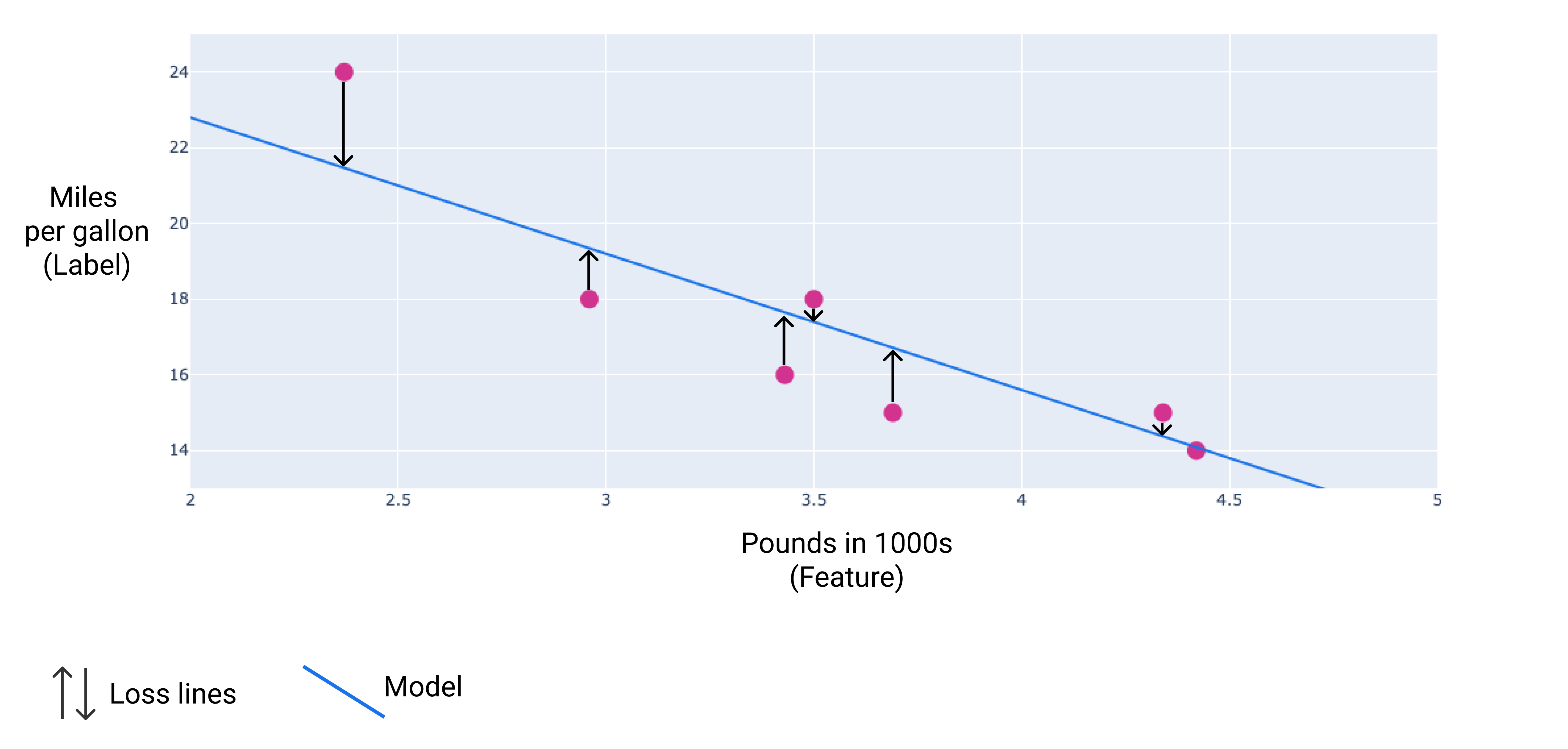

How to find the best function to fit the existing data?
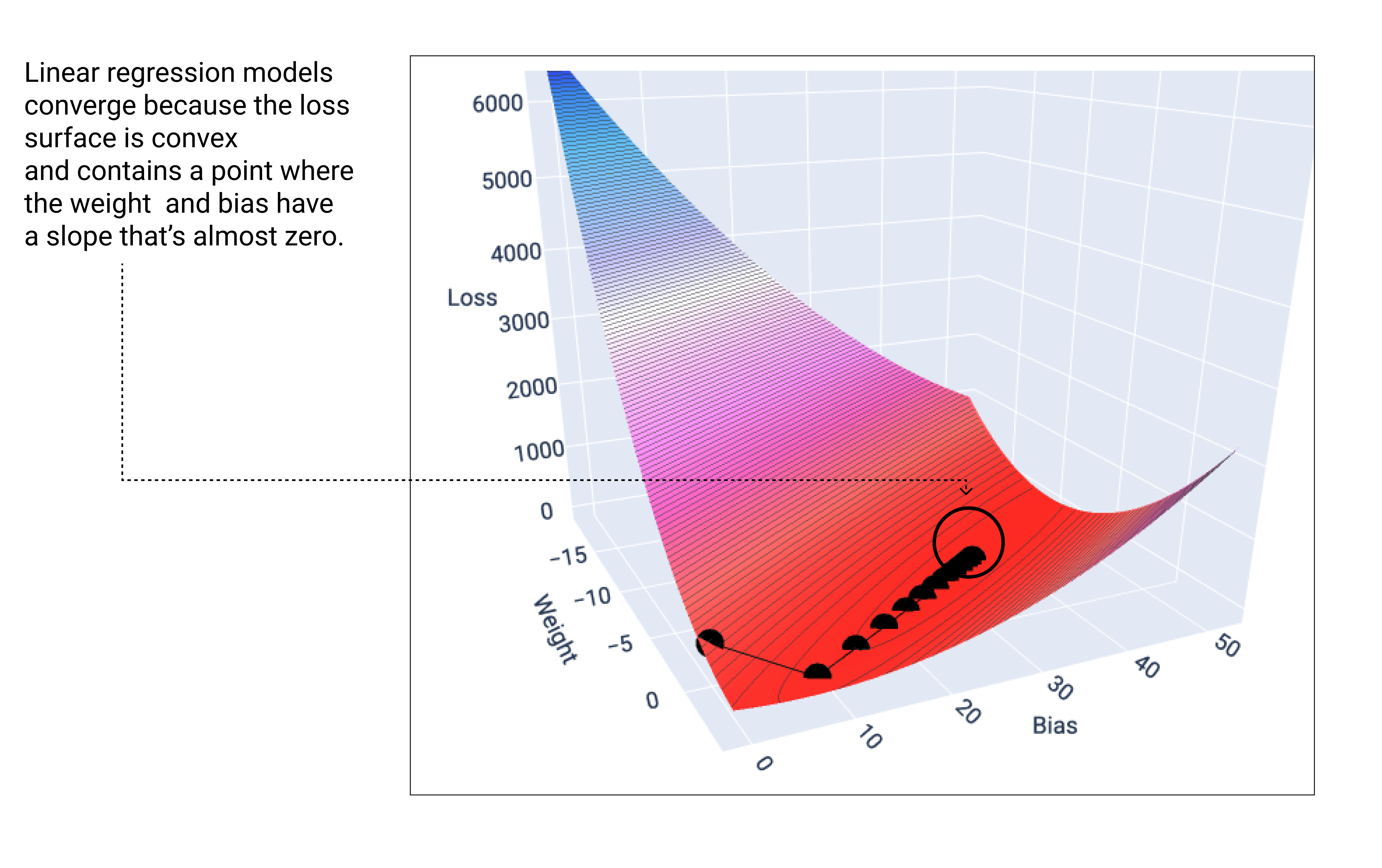
Common machine learning method is Gradient Descent.
The model begins training with randomized weights and biases near zero, and then repeats the following steps:
- Calculate the loss with the current weight and bias.
- Determine the direction to move the weights and bias that reduce loss.
- Move the weight and bias values a small amount in the direction that reduces loss.
- Return to step one and repeat the process until the model can't reduce the loss any further.
Learning rate, local or global minimum...
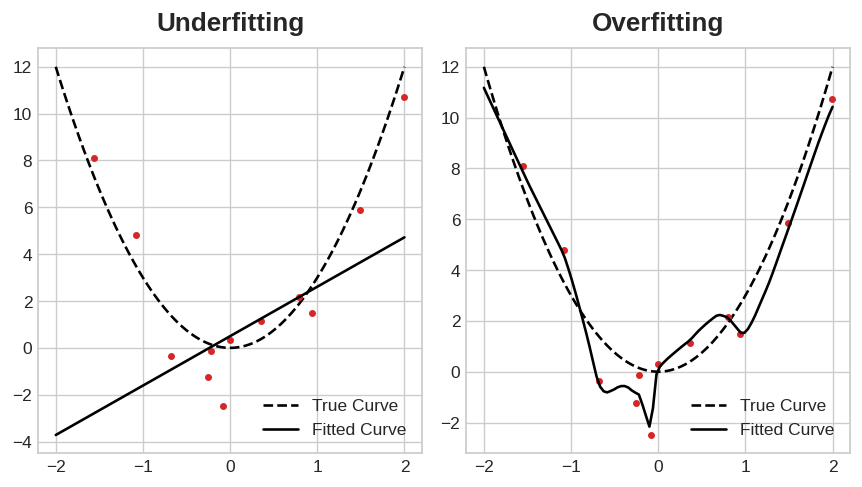
Under and overfitting
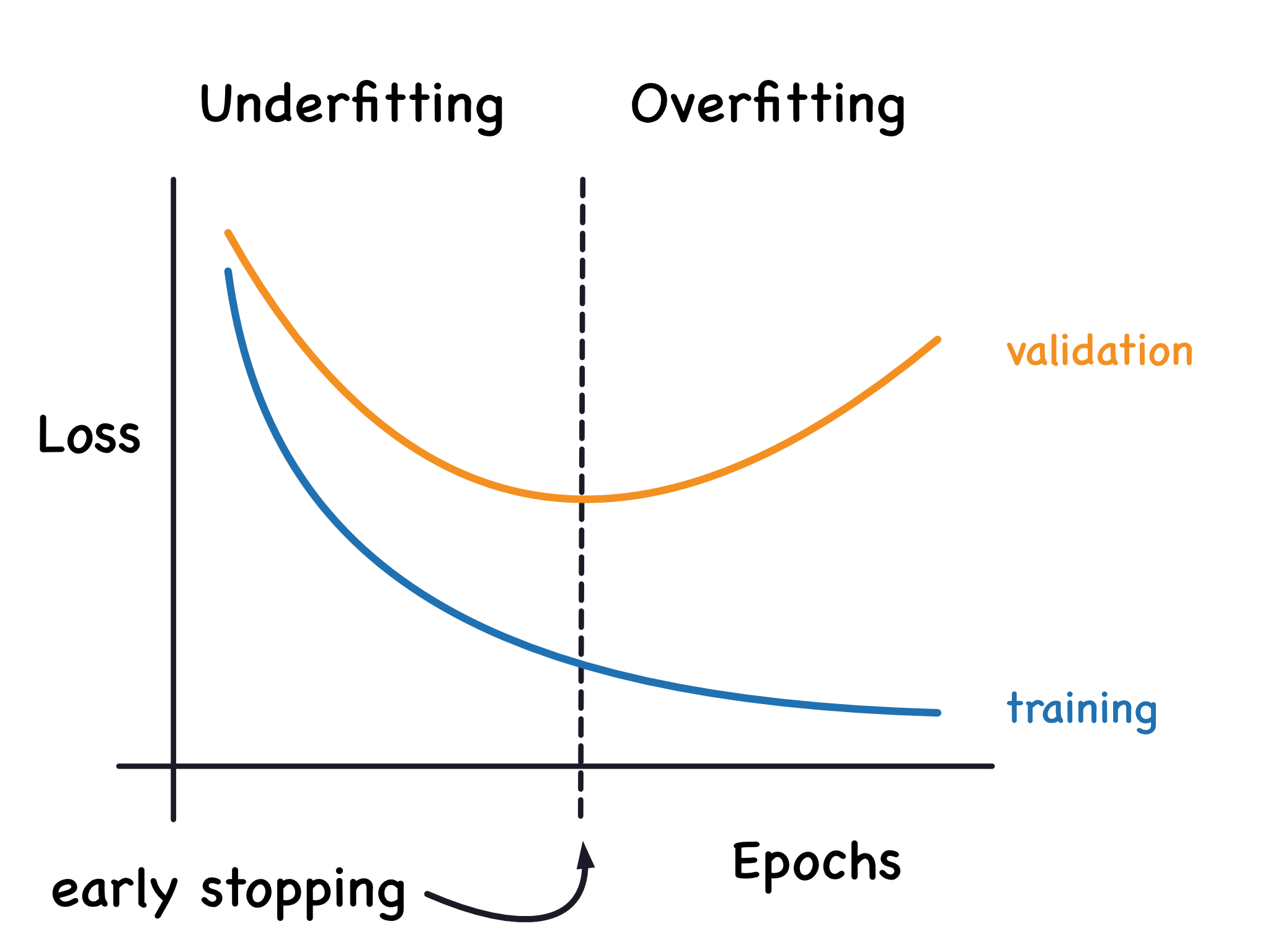
Hyperparameters
Hyperparameters are variables that control different aspects of training. Three common hyperparameters are:
- Learning rate
- Batch size
- Epochs
The learning rate determines the magnitude of the changes to make to the weights and bias during each step of the gradient descent process.
Batch size is a hyperparameter that refers to the number of examples the model processes before updating its weights and bias.
During training, an epoch means that the model has processed every example in the training set once.
Stochastic gradient descent uses only a single example (a batch size of one) per iteration.
Mini-batch stochastic gradient descent is a compromise between full-batch and SGD.
Logistic regression
Many problems require a probability estimate as output. Logistic regression is an extremely efficient mechanism for calculating probabilities.
Logistic regression model can ensure its output represents a probability, always outputting a value between 0 and 1.

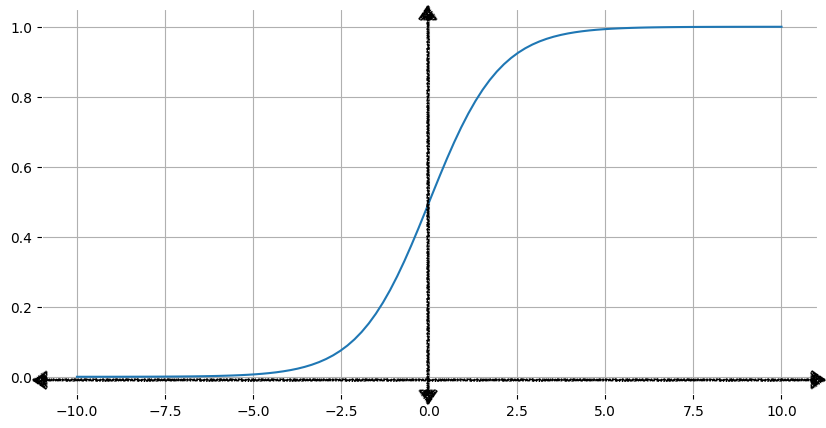
Loss needs to be calculated differently - since change rate is not linear.
The Log Loss equation returns the logarithm of the magnitude of the change, rather than just the distance from data to prediction.

Confusion matrix

Threshold of setting a classification label based on logistic output is important!
Metrics
Accuracy is the proportion of all classifications that were correct, whether positive or negative.
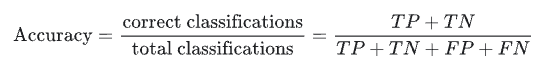
Recall - the true positive rate (TPR), or the proportion of all actual positives that were classified correctly as positives

The false positive rate (FPR) is the proportion of all actual negatives that were classified incorrectly as positives.
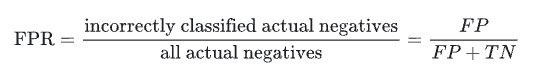
Precision is the proportion of all the model's positive classifications that are actually positive.

Data preparation
Most of the modelling time is spent here. Models only use numerical data (floats, values between 0-1).
One-hot encoding, etc. Imbalanced datasets, data augmentation, synthetic data. Overfitting and Generalization.
Data spliting.
Neural networks - AI
Some data is impossible to predict using the form b+w1x1+w2x2

Neural networks are a family of model architectures designed to find nonlinear patterns in data. During training of a neural network, the model automatically learns the optimal feature crosses to perform on the input data to minimize loss.
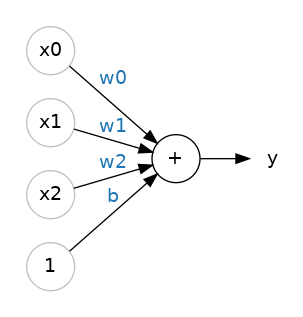
3 weights and bias. One output, with some kind of calculation (activation function).
Layers
Neural networks typically organize their neurons into layers. When we collect together linear units having a common set of inputs we get a dense layer.
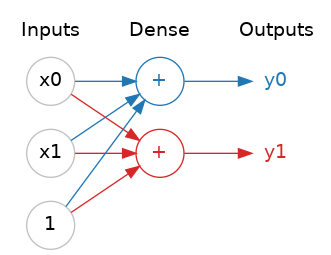
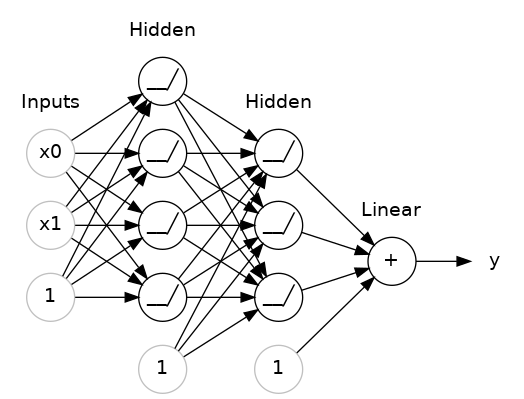
The layers before the output layer are sometimes called hidden since we never see their outputs directly.
Training Neural Network
Backpropagation - the algorithm that implements gradient descent in neural networks.
- During the forward pass, the system processes a batch of examples to yield prediction(s). The system compares each prediction to each label value. The difference between the prediction and the label value is the loss for that example. The system aggregates the losses for all the examples to compute the total loss for the current batch.
- During the backward pass (backpropagation), the system reduces loss by adjusting the weights of all the neurons in all the hidden layer(s).
In calculus terms, backpropagation implements the chain rule. from calculus. That is, backpropagation calculates the partial derivative of the error with respect to each parameter.
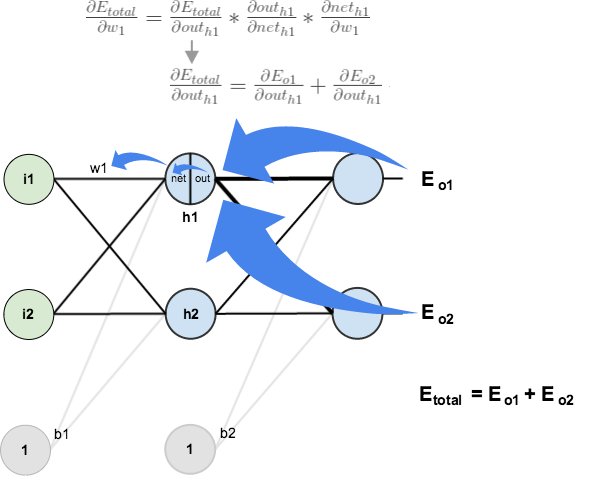
https://mattmazur.com/2015/03/17/a-step-by-step-backpropagation-example/
MNIST image detection model, PyTorch.
The MNIST database of handwritten digits has a training set of 60,000 examples, and a test set of 10,000 examples.
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 32, 3, 1)
self.conv2 = nn.Conv2d(32, 64, 3, 1)
self.dropout1 = nn.Dropout(0.25)
self.dropout2 = nn.Dropout(0.5)
self.fc1 = nn.Linear(9216, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.conv2(x)
x = F.relu(x)
x = F.max_pool2d(x, 2)
x = self.dropout1(x)
x = torch.flatten(x, 1)
x = self.fc1(x)
x = F.relu(x)
x = self.dropout2(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train(args, model, device, train_loader, optimizer, epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
if args.dry_run:
break
Embeddings - vectors
An embedding is a relatively low-dimensional space into which you can translate high-dimensional vectors (one hot encodings).
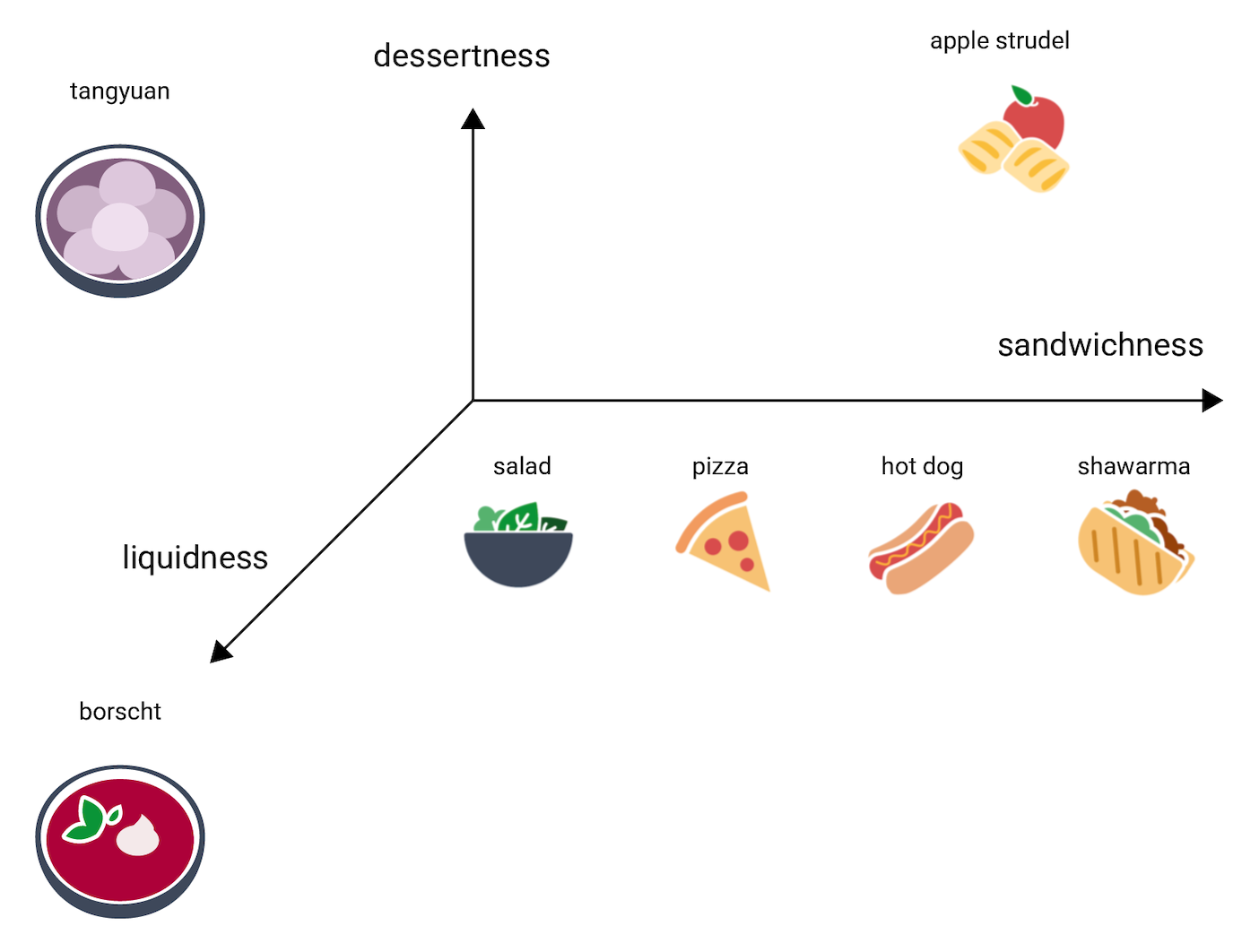
How to find these embeddings?
Turn this into supervised learning problem.
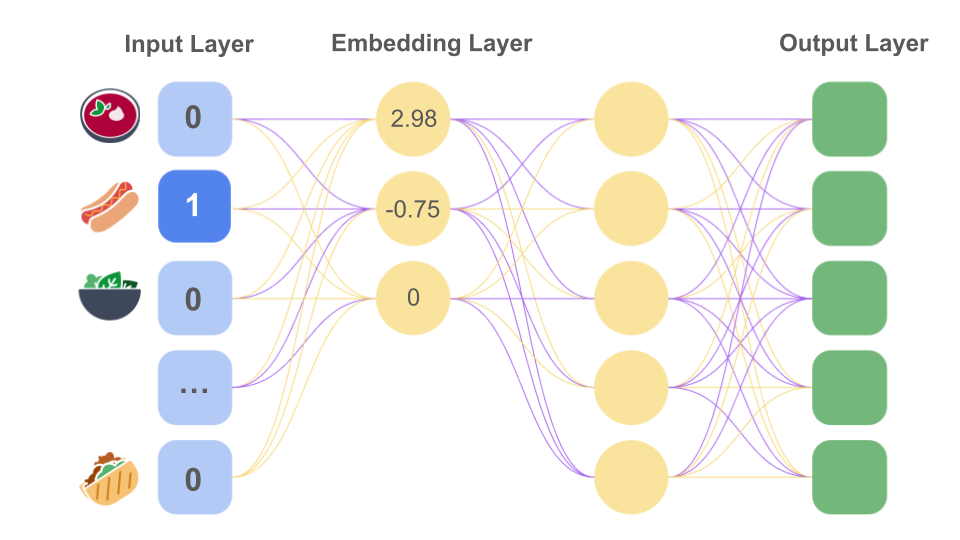
Take many users 5 favorite food examples, hide one of them as label and let network to predict it.
During training, the neural network model will learn the optimal weights for the nodes in the first hidden layer, which serves as the embedding layer. For example, if the model contains three nodes in the first hidden layer, it might determine that the three most relevant dimensions of food items are sandwichness, dessertness, and liquidness.
Word2vec is one of many algorithms used for training word embeddings. It relies on the distributional hypothesis to map semantically similar words to geometrically close embedding vectors. The distributional hypothesis states that words which often have the same neighboring words tend to be semantically similar. Both "dog" and "cat" frequently appear close to the word "veterinarian," and this fact reflects their semantic similarity. As the linguist John Firth put it in 1957, "You shall know a word by the company it keeps."
Contextual embeddings allow for multiple representations of the same word, each incorporating information about the context in which the word is used.
Language Model
A language model estimates the probability of a token or sequence of tokens occurring within a longer sequence of tokens. A token could be a word, a subword (a subset of a word), or even a single character.
When I hear rain on my roof, I _______ in my kitchen.
- 9.4% cook soup
- 5.2% warm up a kettle
- 3.6% cower
- 2.5% nap
- 2.2% relax
An application can use the probability table to make predictions. The prediction might be the highest probability (for example, "cook soup") or a random selection from tokens having a probability greater than a certain threshold.
N-gram language models
N-grams are ordered sequences of words used to build language models, where N is the number of words in the sequence. For example, when N is 2, the N-gram is called a 2-gram (or a bigram); when N is 5, the N-gram is called a 5-gram.
Given two words as input, a language model based on 3-grams can predict the likelihood of the third word.
Humans can retain relatively long contexts. While watching Act 3 of a play, you retain knowledge of characters introduced in Act 1. Similarly, the punchline of a long joke makes you laugh because you can remember the context from the joke's setup.
Longer N-grams would certainly provide more context than shorter N-grams. However, as N grows, the relative occurrence of each instance decreases. When N becomes very large, the language model typically has only a single instance of each occurrence of N tokens, which isn't very helpful in predicting the target token.
Recurrent neural networks (RNN) provide more context than N-grams.
Hidden layers from the previous run provide part of the input to the same hidden layer in the next run.

Large Language Model - LLM
LLMs predict a token or sequence of tokens, sometimes many paragraphs worth of predicted tokens. Contain far more parameters than recurrent models and gather far more context.
LLMs are built using transformers (mostly).
Full transformers consist of an encoder and a decoder:
- An encoder converts input text into an intermediate representation. An encoder is an enormous neural net.
- A decoder converts that intermediate representation into useful text. A decoder is also an enormous neural net.
![]()
To enhance context, Transformers rely heavily on a concept called self-attention. Effectively, on behalf of each token of input, self-attention asks the following question:
"How much does each other token of input affect the interpretation of this token?"
Sentence:
- The animal didn't cross the street because it was too tired.
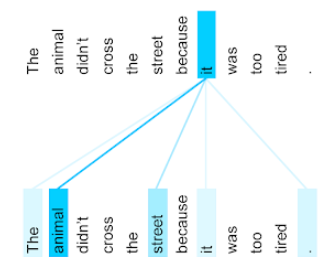
Each self-attention layer is typically comprised of multiple self-attention heads. The output of a layer is a mathematical operation (for example, weighted average or dot product) of the output of the different heads.
Since each self-attention layer is initialized to random values, different heads can learn different relationships between each word being attended to and the nearby words.
![]()
How LLMs are trained?
The primary ingredient in building a LLM is a phenomenal amount of training data (text), typically somewhat filtered.
The residents of the sleepy town weren't prepared for what came next.
Random tokens are removed, for example:
The ___ of the sleepy town weren't prepared for ___ came next.
An LLM is just a neural net, so loss (the number of masked tokens the model correctly considered) guides the degree to which backpropagation updates parameter values.
Transformers contain hundreds of billion or even trillions of parameters. And weirdly size is important - more is better.
Text generation
LLMs are essentially autocomplete mechanisms that can automatically predict (complete) thousands of tokens.
Problems with LLMs
Training an LLM entails many problems, including:
- Gathering an enormous training set.
- Consuming multiple months and enormous computational resources and electricity.
- Solving parallelism challenges.
Using LLMs to infer predictions causes the following problems:
- LLMs hallucinate, meaning their predictions often contain mistakes.
- LLMs consume enormous amounts of computational resources and electricity. Training LLMs on larger datasets typically reduces the amount of resources required for inference, though the larger training sets incur more training resources.
- Like all ML models, LLMs can exhibit all sorts of bias.
Initially we arrive at foundational models. Then these are usually finetuned, distilled (some layers / weights are dropped) and quantized (less precise numbers are used - from float32/16 to int4).
Compared to the brain:
- Human cortex has ca 16B neurons and ca 16T parameters (1000 per neuron)
- GPT3 is ca 2 orders of magnitude smaller
- LLM part of brain is ca 400-700M neurons and ca 400-700T params - about the size of current LLMs
- Vision in brain - ca 3-5B neurons - 3-5T params. Dall-E is at 12B params. But seems to be on par with humans.
WHat does it take
Metas Llama 3, was trained on 24,000 of Nvidia's flagship H100 chips.
That's 24,000 x $30,000 (estimated) = $720 million in GPU hardware alone.
Renting that compute for few months - ca 150M usd.
Meta reports 39.3 million hours of H100 80GB instances to train all 3.1 models (8, 70, 400 B).
Based on AWS pricing 39300000 * 50 / 8 = $245.6M.
Then add on engineers... OpenAI has about 1500 people. Ca 1.5B year.
Prompt Engineering
Prompt engineering enables an LLMs end users to customize the model's output. That is, end users clarify how the LLM should respond to their prompt.
Showing one example to an LLM is called one-shot prompting. Providing multiple examples is called few-shot prompting.
No examples - zero shot. But llms like context - so provide code examples, documentation, existing code and clear instructions.
Prompt design strategies
- Give clear and specific instructions
- Give the models instructions on what to do.
- Make the instructions clear and specific.
- Specify any constraints or formatting requirements for the output.
- Include few-shot examples
- Including prompt-response examples in the prompt helps the model learn how to respond.
- Give the model examples of the patterns to follow instead of examples of patterns to avoid.
- Experiment with the number of prompts to include. Depending on the model, too few examples are ineffective at changing model behavior. Too many examples cause the model to overfit.
- Use consistent formatting across examples
- Add contextual information
- Include information (context) in the prompt that you want the model to use when generating a response.
- Give the model instructions on how to use the contextual information.
- Add prefixes
- Input prefix: Adding a prefix to the input signals semantically meaningful parts of the input to the model. For example, the prefixes "English:" and "French:" demarcate two different languages.
- Output prefix: Even though the output is generated by the model, you can add a prefix for the output in the prompt. The output prefix gives the model information about what's expected as a response. For example, the output prefix "JSON:" signals to the model that the output should be in JSON format.
- Example prefix: In few-shot prompts, adding prefixes to the examples provides labels that the model can use when generating the output, which makes it easier to parse output content.
Let the model complete partial input
- If you give the model a partial input, the model completes that input based on any available examples or context in the prompt.
- Having the model complete an input may sometimes be easier than describing the task in natural language.
- Adding a partial answer to a prompt can guide the model to follow a desired pattern or format.
Break down prompts into simple components
- Break down complex instructions into a prompt for each instruction and decide which prompt to apply based on the user's input.
- Break down multiple sequential steps into separate prompts and chain them such that the output on the preceding prompt becomes the input of the following prompt.
- Break down parallel tasks and aggregate the responses to produce the final output.
Experiment with different parameter values
- Max output tokens - 100 tokens are ca 20 words
- Temperature - randomness. 0 - no randomness, 0.2 - default
- Top-K - For each token selection step, the top-K tokens with the highest probabilities are sampled. Default 40.
- Top-P - if tokens A, B, and C have a probability of 0.3, 0.2, and 0.1 and the top-P value is 0.5, then the model will select either A or B. Default 0.95.
Iteration strategies
- Use different phrasing
- Switch to an analogous task
- Change the order of prompt content
A fallback response is a response returned by the model when either the prompt or the response triggers a safety filter. An example of a fallback response is "I'm not able to help with that, as I'm only a language model."
If the model responds with a fallback response, try increasing the temperature.
- Avoid relying on models to generate factual information.
- Use with care on math and logic problems.
AI assistants in SWE
Top tools are:
- Cursor
- Aider
- Cline
- Windsurf
- V0
- Copilot
- Tabnine
- Codium
And many IDE's have their own solution.
Functionalities
- Autocomplete (on steroids)
- Multi line edits
- Rewrites
- Cursor movement prediction
- Code genration on demand, explanations, refactoring - based on natural language prompts
- terminal command generation
- multi-modal prompts (images)
- multi file edits and generation - software architect
- context manipulation (add files, system prompt, documents, etc)
- code review
Language models - Anthropics Claude 3 Sonnet
Also local models can be used (depending on the hardware). 24+ GB gpu ram or any Apple Silicon mac with enough memory, etc.
Look into ollama, LM Studio, etc.
Use suitable system prompt.
DO NOT GIVE ME HIGH LEVEL SHIT, IF I ASK FOR FIX OR EXPLANATION, I WANT ACTUAL CODE OR EXPLANATION!!! I DON'T WANT "Here's how you can blablabla"
- Be casual unless otherwise specified
- Be terse
- Suggest solutions that I didn't think about—anticipate my needs
- Treat me as an expert
- Be accurate and thorough
- Give the answer immediately. Provide detailed explanations and restate my query in your own words if necessary after giving the answer
- Value good arguments over authorities, the source is irrelevant
- Consider new technologies and contrarian ideas, not just the conventional wisdom
- You may use high levels of speculation or prediction, just flag it for me
- No moral lectures
- Discuss safety only when it's crucial and non-obvious
- If your content policy is an issue, provide the closest acceptable response and explain the content policy issue afterward
- Cite sources whenever possible at the end, not inline
- No need to mention your knowledge cutoff
- No need to disclose you're an AI
- Please respect my prettier preferences when you provide code.
- Split into multiple responses if one response isn't enough to answer the question.
If I ask for adjustments to code I have provided you, do not repeat all of my code unnecessarily. Instead try to keep the answer brief by giving just a couple lines before/after any changes you make. Multiple code blocks are ok.
Use well structured prompts, xml is good choice.
<purpose>
Summarize the given content based on the instructions and example-output
</purpose>
<instructions>
<instruction>Output in markdown format</instruction>
<instruction>Summarize into 4 sections: High level summary, Main Points, Sentiment, and 3 hot takes biased toward the author and 3 hot takes biased against the author</instruction>
<instruction>Write the summary in the same format as the example-output</instruction>
</instructions>
<example-output>
# Title
## High Level Summary
...
## Main Points
...
## Sentiment
...
## Hot Takes (biased toward the author)
...
## Hot Takes (biased against the author)
...
</example-output>
<content>
{...} <<< update this manually
</content>
Use tool configuration files, for Cursor go to https://cursor.directory/
RAG, MCP, Agents - future
- RAG - Retrieval-Augmented Generation (RAG) is the process of optimizing the output of a large language model, so it references an authoritative knowledge base outside of its training data sources before generating a response.
- MCP - The Model Context Protocol is an open protocol that enables seamless integration between LLM applications and external data sources and tools.
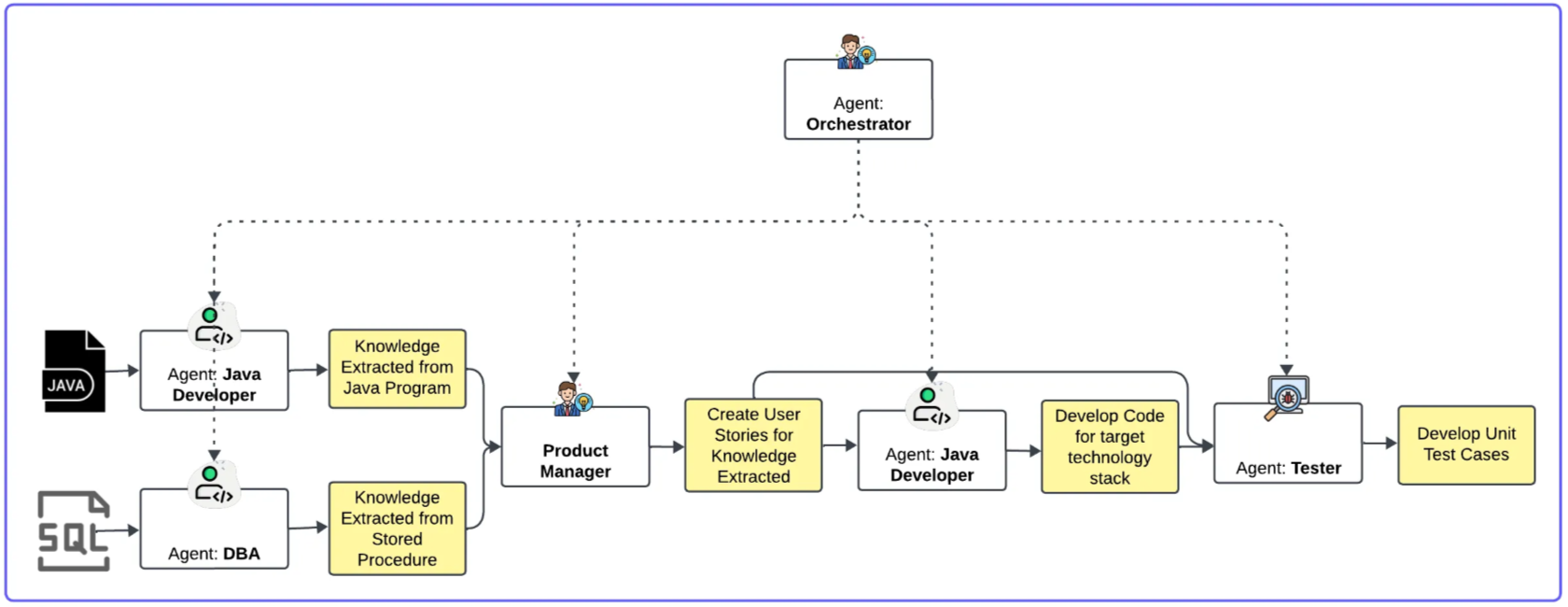
- Agents - When the project demands sequential reasoning, planning, and memory, LLM agents shine.
- Multi agent, orchestration
What's the average daily calorie intake for 2023 in the United States?
Current weather in Tallinn?
How has the trend in the average daily calorie intake among adults changed over the last decade
in the United States, and what impact might this have on obesity rates?
Additionally, can you provide a graphical representation of the trend
in obesity rates over this period?